21个数据科学家面试必须知道的问题和答案
http://blog.csdn.net/er8cjiang/article/details/51027461
问题三:如何验证自己所创建的、用来通过多重回归的定量结果变量生成预测模型的模型?
1、如果该模型预测的值远不在响应变量范围之内,立即可以得出预测或模型有误。
2、如果结果看起来很合理,请检查参数;下面这些代表着预测欠佳或是具有多重共线性:有预测结果相反的迹象、值异常大或异常小、或者在模型填入新数据时发现结果不一致。
3、通过填入新数据、使用模型来进行预测,以及使用确定系数(R平方)作为模型有效性衡量。
4、使用数据分割的方式,为预测模型参数作出一个单独的数据集与一个验证预测的数据集。
5、如果数据集包含少量实例,使用刀切法重采样;并使用R平方和均方误差(MSE)来衡量有效性。
问题四:解释一下查准率与查全率的概念。它们与ROC曲线有什么关系?
查准率和查全率(Precision and Recall): 计算查准率与查全率实际上非常简单。想象一下在1万个案例中,有100个阳性案例。想要知道哪些是阳性案例,选出200个在其中选择,可以确保找到这100个阳性案例的机会更大。记录预测的ID,在拿到实际结果时,总结一下判断正确与错误的总次数。关于正确和错误共有四种判断方式:
TN(真阴性):本来是负样例的案例被分类成负样例。
TP(真阳性):本来是正样例的案例被分类成正样例。
FN(伪阳性):本来是正样例的案例,被错分成负样例,又称误报、误判。
FP(伪阴性):本来是负样例的案例,被错分成正样例,又称漏报、漏判。
| 预测为阴性 | 预测为阳性 | |
|---|---|---|
| 阴性案例 | TN:9760 | FP: 140 |
| 阳性案例 | FN:40 | TP: 60 |
预测的正确率是百分之多少? 你可以回答:“正确率”为1万分之(9,760+60),也就是98.2%。
查出的阳性案例占实际的多大比例? 你可以回答:“查全率”是100分之60,也就是60%。
预测为阳性的案例正确率是多少? 你可以回答:“查准率”是200分之60,也就是30%。
ROC曲线表现了敏感性(查全率)与特异性(不准确)之间的关系,通常用于衡量二值分类器(binary classifiers)的性能。但是,在处理高度倾斜的数据集时,PR曲线(Precision-Recall)更能代表性能。可以参考Quora 的回答:ROC曲线和RP曲线之间的区别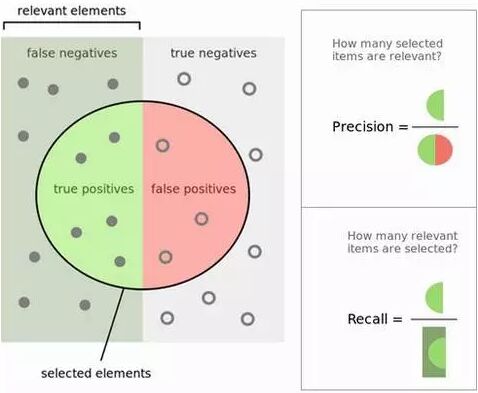
问题五:如何证明你对一个算法作出的改进确实算是改进,而没有其他作用?
确保在选择用作性能对比的测试数据时,不带入选择性偏差。
确保测试数据的种类充足,以代表真实情况下的数据(剔除过拟合)。
确保遵守“可控实验”准则,也就是说在对比性能时,运行初始算法与新算法的测试环境(硬件等)必须相同。
确保在使用类似的结果时,所得出的结论是可重复的。
检查结果是否反映了本地最大值/最小值,或者全局最大值/最小值。
实现上述指导方针的一个常见办法就是通过A/B测试,确保两种版本的算法都运行在类似的环境中,并且运行了相当长的时间,并将实际数据随机投入这两种算法中。这种方法在网络分析中尤为常见。
问题九:解释一下重采样方法是什么,它为什么很有用?再解释一下其局限
在经典的统计参数测试中,会对观察到的统计进行对比,得出理论抽样分布结果。重采样方法是面向数据的方法,而不是基于相同样本、进行重复采样的理论方法。
重采样方法指的是执行下面的方式之一:
1、通过可用数据的子集(刀切法)估算样本统计的精度(中位数、方差、百分位数),或者通过替换一组数据点,随机获取(bootstrapping算法)。
2、在执行重大测试是,交换数据点的标签(排列测试,也被称为精确检验、随机测试或者重新随机测试)。
3、通过使用随机子集(bootstrapping算法、交叉验证)来验证模型。 关于bootstrapping算法、刀切法请参见Wiki的概念,还可以参考如何通过Bootstrap和Apache Spark验证假定一文
问题十:误报很多比较好,还是漏报很多比较好?解释一下原因
这取决于我们希望解决的问题所在的领域。
在医学检测领域,漏报可能因为让病人和医生误以为疾病不存在,而错误地感到放心,但实际上病症是存在的。有时候,这会导致病人缺乏足够或充分的治疗。因此在这个领域,误报更多会比较好。
对于垃圾邮件过滤机制,误报会导致在垃圾邮件过滤时,错误地拦截邮件,将正确的邮件消息误判成垃圾邮件,从而导致邮件无法正确到达目标者手中。尽管大多反垃圾邮件的战略能够拦截或筛选出很大一部分不必要的邮件,但不引入重大的误判对相应机制的要求更高。因此,我们希望多些漏判,而不是误判。
问题十一:选择性偏差是什么?为什么很重要,又要如何避免?
一般来讲,选择性偏差是一种有问题的情况,由于样本数量随机不够而导致引入错误。举个例子:针对给定100个测试样本的案例,其中在分类时按照60/20/15/5 分为四类,但各类实际上来讲数量应当是平均的,那么给定模型就有可能在确定预测因素作出错误的假设。避免样本不够随机是解决偏差的最佳方式;不过在不起作用时,可以借助类似重采样、boosting和加权等方式,来解决这一问题。
附加题:解释什么是过拟合,你如何控制它?尝试寻找最简单的可能假设
- 正则化(增加模型复杂度惩罚)
- 随机测试(随机类变量,对此 数据试试你的方法-如果你发现一样的结果,那么出错了)
- 嵌套交叉验证(在一个水平上选择特征,然后在外层交叉验证中运行整个方法)
- 调整错误发现率
- 使用可重复使用抵抗方法-2015年提出的一种突破性方法
也可参考:
- 数据挖掘和数据科学的大忌:过拟合
- 避免过拟合的伟大创意:可重复使用抵抗以保留适应数据分析的有效性
- 使用可重复使用抵抗克服过拟合:保留适应数据分析的有效性
- 过拟合以及如何避免的11和巧妙方法
- 标签:过拟合
问题十二:给出你如何使用试验设计回答用户行文的问题
第一步:制定研究问题:
什么是页面加载时间对用户满意评分的影响?
第二步:识别变量:
我们确定因果.独立变量-网页加载时间,依赖变量-用户满意评分
第三步:生成假设:
较低的网页下载时间对网页的用户满意评分产生较高的影响.下面是我们分析的网页加载时间因素.
第四步:确定试验设计
我们认为试验的复杂度,即在同一时间一个因素变化或同一时间多个因素变化情况下,我们使用析因设计(2^K设计).基于客观(比较,筛选,响应面)类型和因子数量被选择的设计.
我们同时也识别Within-participants设计,Between-participants设计 ,以及混合模型.有两个版本的页面,一个在左边带有Buy按钮(称为行为),另一个在右边有这个按钮.
Within-participants设计-用户组看到的两个版本 .
Between-participants设计-一个用户组看到版本A,另一个用户组看到版本B.
第五步:制定试验任务和步骤:
这步的细节描述包含,实践中使用衡量用户行,目标的工具;成功指标需要界定.收集关于用户参与的定性数据用于统计分析.
第六步:决定操作和测量:
操作:因子水平之一,将得到控制,其他的将被操作.我们还确定行为测量:
延时-提示和行为发生间的时间(用户在呈现物品后多久会购买)
频数-行为发生的次数(时间内特定网页用户点击的次数)
持续时间-特定行为的持续时间(添加所有产品的时间)
强度-行为发生的动力(用户购买产品有多快)
第七步:分析结果:
根据观测结果,如相比网页加载时间有多用户满意度评分,识别用户行为数据,并支持假设或矛盾
问题十三:”长”(“高”)格式数据与”宽”个是数据之前异同?
在大多数数据挖掘/数据科学应用中记录(行)多过特征(列),这样数据在一些时候称为”高”(“长”)数据.
在一些应用中,如基因组学或生物信息学中,你可能只有小量的记录(病人),比如100,但是每个病人可能有20,000的观测.对于高数据的标准方法会导致过拟合,所以需要特殊方法.
Jieping Yeah展示稀疏筛选用于减少精确数据
这个问题不仅仅是重塑数据(这里有一些有用的R包),而是通过减少特征数量避免误判来发现最相关的.
稀疏统计学习:Lasso和正则化中包含lasso等降维方法.

问题十六:你会如何筛选离群值,如果你找到了你应该怎么办?
一些方法可以用于筛选离群值,例如Z-scores,修正Z-scores,箱线图,Grubb测试,Tietjen-Moore测试指数平滑,Kimber测试指数分布窗口移动过滤算法( Kimber test for exponential distribution and moving window filter algorithm)等等.然而两个健壮的方法是:
四分位距
那么对于给定数据集,一个数据点是离群值,那么其1.5IQR低于第一四分位数(Q1)高于第三四分位数(Q3).
- High=(Q3)+1.5IQR
- Low=(Q1)-1.5IQR
杜克方法
它采用四分位距过滤非常大或非常小的数字.和上述方法实际上是相同方法,不同之处是他采用隔离的概念.两个隔离的值是:
- Low outliers = Q1 - 1.5(Q3 - Q1) = Q1 - 1.5(IQR)
- High outliers = Q3 + 1.5(Q3 - Q1) = Q3 + 1.5(IQR)
任何一个超过隔离的是离群值.
当你发现异常值,你不应该在没有定性评估移除它,因为这样你改变了数据,使其不在纯.理解分析和”为什么问题-为什么一个离群点和其他数据点是不同的”重要性是非常重要的.
原因是至关重要的.如果离群值归因于误差,你可以扔掉,但是如果他们以为一种新趋势,模式或透露宝贵信息的数据,你需要保留.
问题十七:你将如何使用极值理论,蒙特卡洛模拟或数理统计(或其他东西)正确估计一个非常罕见的事件的机会呢
极值理论(EVT)重点是罕见事件或极端事件,而不是传统方法统计平均信息.EVT指数由三种分布需要从一些分布中建模随机观测集合的极端数据点:Gumble,Frechet和Weibull分布,也成为极值分布.
EVT指出,如果你从给定分布生成N个数据集,然后创建一个包含这N个数据集中最大值的新数据集,这个新数据集将被EVD分布中的一个精确描述:Gumbel,Frechet,或Weibull.广义极值分布(GEV)是结合三个EVT模型的EVD模型.
了解如果对数据建模,我们可以使用模型拟合数据并评估.一旦最优拟合模型发现,可以分析性能,包括计算可能性.
问题十八:什么是推荐引擎? 它是如何工作的?
通常以两种方式产生推荐:协同过滤或基于内容过滤.
协同过滤算法基于用户过去行为(之前购买物品,观看电影,评分等等)建立模型,对当前或其他用户做决策.模型用于预测用户可能喜欢的物品(物品评分).
基于内容过滤方法使用一个物品特征推荐额外具有相似属性的物品.这些方法通常在混合推荐系统中组合使用.
这是两种方法用于流行音乐推荐系统-Last.fm和Pandora Radio的比较.
- Last.fm通过观察用户顶起听什么频道和独立音轨,和其他用户行为比较推荐歌曲.Last.fm会播放没有在用户库中出现过,但其他相似兴趣用户经常听的可取.作为这种方法利用用户行为,这是协同过滤技术的例子.
- Pandora 利用歌曲或艺术家的属性(Music Genome Project提供的400个属性)创建播放相似属性的站.用户反馈用户重定义站的结果,淡化用户不喜欢特定歌曲的属性,并且强化用户喜欢其他歌曲的属性.这是基于内容过滤的例子.
Dataconomy的 Introduction to Recommendation Engines 和Toptal的 building a Collaborative Filtering Recommendation Engine是非常好的书.对于最新推荐系统的研究,查看 ACM RecSys conference.
问题十九:解释什么是假阳性和假阴性.为什么要强调区分它们?
在二元分类(医疗测试)中,假阳性是当一个算法(测试)明确条件存在,而实际上是不存在的.假阴性是当一个算法(测试)明确没有一个条件,但是实际中存在.
统计假设检验假阳性称为第一类错误,假阴性-第二类错误.
区分和处理假阳性和假阴性的不同显然是非常重要的.因为这样错误的成本显然是不同的.
例如,如果对严重疾病测试为假阳性(测试结果为疾病,但人是健康的),那么一个额外的测试都将做正确的诊断.然而,如果一个测试是假阴性,(测试结果健康,但是人是病的),人可能因为结果而死亡.
问题二十:你使用的可视化工具?你怎么看Tableau?R?SAS?如何在图表有效地展现五维数据
有许多优秀的数据可视化工具.R,Python ,Tableau和Excel是数据科学家最常用的.
这是KDnuggets有用的资源:
有许多方式在图表中展现超过两维数据.第三维可以用3D散点图旋转显示得到.你可以使用颜色,阴影,形状,大小.动画可以用时间维度有效的显示.
对于超过五维数据,一个方法是平行坐标
可以参阅:
- Quora: 什么是可视化高维数据的最佳方式
- Georges Grinstein和他同事对 高维可视化 的创举
当然,如果你有了大量维度,最好是减少维度和特征数量。