第一层次”Operating”:会使用工具
这个层次的工程师,对常用的模型比较熟悉,来了数据以后,好歹能挑个合适的跑一下。
达到这个层次,其实门槛不高。早些年,您只要掌握了什么叫LDA、哪叫SVM,再玩过几次libnear、mahout等开源工具,就可以拿到数据后跑个结果出来。到了深度学习时代,这件事儿似乎就更简单了:管它什么问题,不都是拿神经网络往上堆嘛!很近,经常会遇到一些工程师,成功地跑通了Tensorflow的demo后,兴高采烈地欢呼:我学会深度学习了,我明天就统治人类了!
这事要真这么简单,我是茄子。任凭你十八般开源工具用的再熟,也不可能搞出个战胜柯洁的机器人来。这里要给大家狠狠浇上一盆冷水:进入这个领域的人,都要先了解一个“没有免费的午餐定理”,这个定理的数学表达过于晦涩,我们把它翻译成并不太准确的文艺语言:
如果有两个模型搞一次多回合的比武,每个回合用的数据集不同,而且数据集没什么偏向性,那么很后的结果,十有八九是双方打平。
管你是普通模型、文艺模型还是2B模型,谁也别瞧不起谁。考虑一种极端情况:有一个参赛模型是“随机猜测”,也就是无根据地胡乱给个答案,结果如何呢?对,还是打平!所以,请再也不要问“聚类用什么算法效果好”这样的傻问题了。
这就很尴尬了!因为掌握了一堆模型并且会跑,其实并没有什么卵用。当然,实际问题的数据分布,总是有一定特点的,比方说人脸识别,图中间怎么说都得有个大圆饼。因此,问“人脸识别用什么模型好”这样的问题,就有意义了。而算法工程师的真正价值,就是洞察问题的数据先验特点,把他们表达在模型中,而这个,就需要下一个层次的能力了。
会使用工具,在算法工程师中仅仅是入门水平,靠这两把刷子解决问题,就好比杀过两只鸡就想做腹腔手术一样,不靠谱儿程度相当高。如果不是在薪酬膨胀严重的互联网界,我觉得20万是个比较合理的价格。
第二层次”Optimization”:能改造模型
这个层次的工程师,能够根据具体问题的数据特点对模型进行改造,并采用相应合适的很优化算法,以追求的效果。
不论前人的模型怎么美妙,都是基于当时观察到的数据先验特点设计的。比如说LDA,就是在语料质量不高的情况下,在PLSA基础上引入贝叶斯估计,以获得更加稳健的主题。虽说用LDA不会大错,但是要在你的具体问题上跑出的效果,根据数据特点做模型上的准确改造,是不可避免的。
互联网数据这一现象更加明显,因为没有哪两家公司拥有的数据是相似的。百度的点击率模型,有数十亿的特征,大规模的定制计算集群,独特的深度神经网络结构,你能抄么?抄过来也没用。用教科书上的模型不变应万变,结果只能是刻舟求剑。
改造模型的能力,就不是用几个开源工具那么简单了,这需要有两方面的素养:
一、深入了解机器学习的原理和组件。机器学习领域,有很多看似不那么直接有用的基础原理和组件。比方说,正则化怎么做?什么时候应该选择什么样的基本分布?(如下表) 贝叶斯先验该怎么设?两个概率分布的距离怎么算?当你看到前辈高人把这些材料烹调在一起,变成LDA、CNN这些成品菜肴端上来的时候,也要想想如果自己下厨,是否了解食材,会不会选择和搭配。仅仅会吃几个菜,说出什么味道,离好厨师差的还远着呢。 二、熟练掌握很优化方法。机器学习从业者不懂很优化,相当于武术家只会耍套路。这就跟雷公太极和闫芳大师一样,实战起来一定是鼻青脸肿。管你设计了一个多牛逼的模型,如果无法在有限的计算资源下找出很优解,那么不过是个花瓶罢了。
二、熟练掌握很优化方法。机器学习从业者不懂很优化,相当于武术家只会耍套路。这就跟雷公太极和闫芳大师一样,实战起来一定是鼻青脸肿。管你设计了一个多牛逼的模型,如果无法在有限的计算资源下找出很优解,那么不过是个花瓶罢了。
最优化,是机器学习很、很、很重要的基础。你要知道,在目标函数及其导数的各种情形下,应该如何选择优化方法;各种方法的时间空间复杂度、收敛性如何;还要知道怎样构造目标函数,才便于用凸优化或其他框架来求解。而这些方面的训练,要比机器学习的模型还要扎实才行。
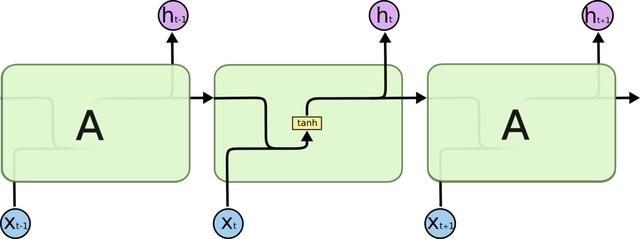
拿大家以为”以不变应万变”的深度学习举个例子。用神经网络处理语音识别、自然语言处理这种时间序列数据的建模,RNN(见上图)是个自然的选择。不过在实践中,大家发现由于“梯度消失”现象的存在,RNN很难对长程的上下文依赖建模。而在自然语言中,例如决定下面的be动词是“is”还是“are”这样的问题,有可能往前翻好多词才能找到起决定作用的主语。怎么办呢?天才的J. Schmidhuber设计了带有门结构的LSTM模型(见下图),让数据自行决定哪些信息要保留,那些要忘掉。如此以来,自然语言的建模效果,就大大提高了。大家初看下面两张RNN与LSTM的结构对比,面对凭空多出来的几个门结构可能一头雾水,唯有洞彻其中的方法论,并且有扎实的机器学习和很优化基础,才能逐渐理解和学习这种思路。
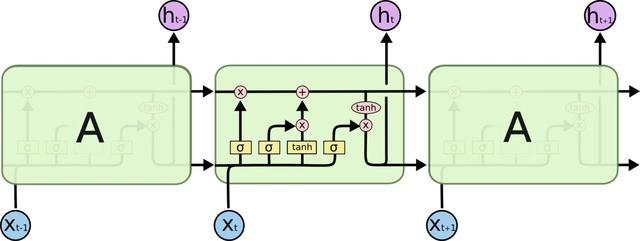
当然,LSTM这个模型是神来之笔,我等对此可望不可及。不过,在这个例子里展现出来的关键能力:根据问题特点调整模型,并解决优化上的障碍,是一名合格的算法工程师应该追求的能力。年薪50找到这样的人,是物有所值的。
第三层次”Objective”:擅定义问题
这个层次的工程师(哦,似乎叫工程师不太合适了),扔给他一个新的实际问题,可以给出量化的目标函数。
当年,福特公司请人检修电机,斯坦门茨在电机外壳画了一条线,让工作人员在此处打开电机迅速排除了故障。结账时,斯坦门茨要1万美元,还开了个清单:画一条线,1美元;知道在哪儿画线,9999美元。
同样的道理,在算法领域,很难的也是知道在哪里画线,这就是对一个新问题构建目标函数的过程。而有明确的量化目标函数,正是科学方法区别于玄学方法、神学方法的重要标志。
目标函数,有时能用一个解析形式(Analytical form)写出来,有时则不能。比方说网页搜索这个问题,有两种目标函数:一种是nDCG,这是一个在标注好的数据集上可以明确计算出来的指标;另一种则是人工看badcase的比例,显然这个没法用公式计算,但是其结果也是定量的,也可以作为目标函数。
定义目标函数,初听起来并没有那么困难,不就是制定个KPI么?其实不然,要做好这件事,在意识和技术上都有很高的门槛。
一、要建立“万般皆下品、唯有目标高”的意识。一个团队也好、一个项目也好,只要确立了正确的、可衡量的目标,那么达到这个目标就只是时间和成本的问题。假设nDCG是搜索的正确目标函数,那么微软也好、Yahoo!也好,迟早也能追上Google,遗憾的是,nDCG这个目标是有点儿问题的,所以后来这两家被越拉越远。
所谓“本立而道生”:一个项目开始时,总是应该先做两件事:一是讨论定义清楚量化的目标函数;二是搭建一个能够对目标函数做线上A/B测试的实验框架。而收集什么数据、采用什么模型,倒都在其次了。
二、能够构造准确(信)、可解(达)、优雅(雅)的目标函数。目标函数要尽可能反应实际业务目标,同时又有可行的优化方法。一般来说,优化目标与评测目标是有所不同的。比如说在语音识别中,评测目标是“词错误率”,但这个不可导所以没法直接优化;因此,我们还要找一个“代理目标”,比如似然值或者后验概率,用于求解模型参数。评测目标的定义往往比较直觉,但是要把它转化成一个高度相关,又便于求解的优化目标,是需要相当的经验与功力的。在语音建模里,即便是计算似然值,也需要涉及Baum-Welch等比较复杂的算法,要定义清楚不是简单的事儿。
优雅,是个更高层次的要求;可是在遇到重大问题时,优雅却往往是不二法门。因为,往往只有漂亮的框架才更接近问题的本质。关于这点,必须要提一下近年来很让人醍醐灌顶的大作——生成对抗网络(GAN)。
GAN要解决的,是让机器根据数据学会画画、写文章等创作性问题。机器画画的目标函数怎么定?听起来是一头雾水。我们早年做类似的语音合成问题时,也没什么好办法,只能找人一句句听来打分。令人拍案叫绝的是,Ian GoodFellow在定义这个问题时,采取了下图的巧妙框架:
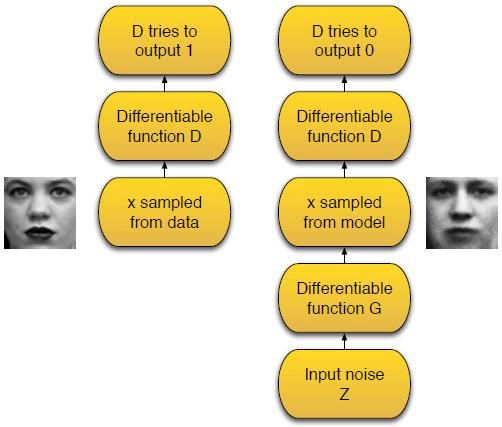
既然靠人打分费时费力,又不客观,那就干脆让机器打分把!好在让机器认一幅特定语义的图画,比如说人脸,在深度学习中已经基本解决了。好,假设我们已经有一个能打分的机器D,现在要训练一个能画画的机器G,那就让G不断地画,D不断地打分,什么时候G的作品在D那里得分高了,就算是学成了。同时,D在此过程中也因为大量接触仿品而提升了鉴赏能力,可以把G训练得更好。有了这样定性的思考还不够,这样一个巧妙设计的二人零和博弈过程,还可以表示成下面的数学问题:

这样一个目标,优雅得象个哲学问题,却又实实在在可以追寻。当我看到这个式子时,顿时觉得教会机器画画是个不太远的时间问题了。如果你也能对这样的问题描述感到心旷神怡,就能体会为什么这才是很难的一步。
一个团队的定海神针,就是能把问题转化成目标函数的那个人——哪怕他连开源工具都不会用。100万找到这样的人,可真是捡了个大便宜。
在机器学习领域,算法工程师脚下的进阶之路是清晰的:当你掌握了工具、会改造模型,进而可以驾驭新问题的建模,就能成长为很的人才。沿着这条路踏踏实实走下去。