1.6.1 熵的概念
熵和概率十分相近,但又不同。概率是真实反映变化到某状态的确信度。而熵反映的是从某时刻到另一时刻的状态有多难以确定,即熵反应的事物的不确定性。阻碍生命的不是概率,而是熵。
信息熵
信息论的开山祖师爷Shannon明确告诉我们,信息的不确定性可以用熵来表示:
对于一个取有限个值的随机变量X,如果其概率分布为:$$ P(X=x_i)=p_i,i=1,2,3...n $$。
那么随机变量X的熵可以用以下公式描述:
$$ H(X)=-\sum_{i=1}^n p_ilog_2(p_i) $$
举个例子,如果一个分类系统中,类别的标识是c 取值情况是 $$ c_1,c_2,...c_n $$,n为类别的总数。那么此分类系统的熵为:
$$ H(c)=-\sum_{i=1}^n p(c_i)log_2p(c_i) $$
更特别一点,如果是个二分类系统,那么此系统的熵为:
$$ H(c)=-p(c_0)log_2p(c_0)-p(c_1)log_2p(c_1)$$
其中,$$ p(c_0), p(c_1) $$ 分别表示正负样本出现的概率。
条件熵(Conditional Entropy)与信息增益(Information Gain)
前面谈到,信息的不确定性我们用熵来进行描述。很多时候,我们渴望不确定性,渴望明天又是新的一天,希望寻找新的刺激与冒险,所谓的七年之庠就是最好的例子。但是又有很多时候,我们也讨厌不确定性,我们又要竭力去消除系统的不确定性。
那怎么样去消除系统的不确定性呢?当我们知道的信息越多的时候,自然随机事件的不确定性就越小。举个简单的例子:
如果投掷一枚均匀的筛子,那么筛子出现1-6的概率是相等的,此时,整个系统的熵可以表述为:
$$ H(c)=-\dfrac 1 6 log_2 \dfrac 1 6 * 6=log_2 6 $$
如果我们加一个特征,告诉你掷筛子的结果出来是偶数,因为掷筛子出来为偶数的结果只可能为2,4,6,那么此时系统的熵为:
$$ H(c)=-\dfrac 1 3 log_2 \dfrac 1 3 * 3=log_2 3 $$
因为我们加了一个特征x:结果为偶数,所以整个系统的熵减小,不确定性降低。
来看下条件熵的表达式:
当特征x被固定为值$$ x_i $$时,条件熵为:$$ H(c|x=x_i) $$
当特征X的整体分布情况被固定时,条件熵为: $$ H(c|X) $$
不难看出:
$$ H(c|X)=-p(x=x_1)H(c|x=x_1)-p(x=x_2)H(c|x=x_2)-...p(x=x_n)H(c|x=x_n) $$
$$ =- \sum{i=1}^n p(x=x_i)H(c|x=x_i) = -\sum{i=1}^n p(x=x_i)p(c|x=x_i) log_2p(c|x=x_i) $$
$$ = -\sum_{i=1}^n p(c,x_i) log_2p(c|x=x_i) $$
其中,n为特征X所出现所有种类的数量。
那么因为特征X被固定以后,给系统带来的增益(或者说为系统减小的不确定度)为:
$$ IG(X)=H(c)-H(c|X)=-\sum{i=1}^n p(c_i)log_2p(c_i)+ \sum{i=1}^n p(x=x_i)H(c|x=x_i) $$
举个例子:文本分类系统中的特征X, 那么X有几个可能的值呢?注意X是一个固定的特征,比如关键词“经济”,当我们说特征“经济”可能的取值时,实际上只有两个,要么出现,要么不出现。假设x代表x出现,而$$\bar x $$表示x不出现。注意系统包含x但x不出现与系统根本不包含x可是两回事。
因此固定X时系统的条件熵为:
$$ H(c|X)=-p(x)H(c|x)-p(\bar x)H(c|\bar x)$$
特征X给系统带来的信息增益(IG)为
:$$ IG(X)=H(c)-H(c|X)=-\sum{i=1}^n p(c_i)log_2p(c_i)+ p(x)\sum{i=1}^n p(ci|x)log_2p(c_i|x) + p(\bar x)\sum{i=1}^n p(c_i|\bar x)log_2p(c_i|\bar x) $$
式子看上去很长,其实计算起来很简单,都是一些count的操作。$$ -\sum_{i=1}^n p(c_i)log_2p(c_i) $$这一项不用多说,就是统计各个类别的概率,将每个类别的样本数量除以总样本量即可。
$$ p(x)\sum_{i=1}^n p(c_i|x)log_2p(c_i|x) $$ 这一项,p(x)表示特征在样本中出现的概率,将特征出现的次数除以样本总量即可。
$$ p(c_i|x) $$表示特征出现的情况下,每个类别的概率分别为多少,也全是count操作, $$ p(c_i|\bar x) $$ 操作以此类推。
信息增益做特征选择的优缺点
先说说优点:
1.信息增益考虑了特征出现与不出现的两种情况,比较全面,一般而言效果不错。
2.使用了所有样例的统计属性,减小了对噪声的敏感度。
3.容易理解,计算简单。
主要的缺陷:
1.信息增益考察的是特征对整个系统的贡献,没有到具体的类别上,所以一般只能用来做全局的特征选择,而没法针对单个类别做特征选择。
2.只能处理连续型的属性值,没法处理连续值的特征。
3.算法天生偏向选择分支多的属性,容易导致overfitting。
信息增益比(Infomation Gain Ratio)
前面提到,信息增益的一个大问题就是偏向选择分支多的属性导致overfitting,那么我们能想到的解决办法自然就是对分支过多的情况进行惩罚(penalty)了。于是我们有了信息增益比,或者说信息增益率:
特征X的熵:
$$ H(X)=-\sum_{i=1}^n p_ilog_2(p_i) $$
特征X的信息增益:$$ IG(X)=H(c)-H(c|X) $$
那么信息增益比:$$ g_r=\dfrac {H(c)-H(c|X)} {H(X)} $$
在决策树算法中,ID3使用信息增益,C4.5使用信息增益比。
Gini系数
Gini系数是一种与信息熵类似的做特征选择的方式,可以用来数据的不纯度。在CART(Classification and Regression Tree)算法中利用基尼指数构造二叉决策树。
Gini系数的计算方式如下:
在分类问题中,假设有i个类,样本点属于第i类的概率是$$ p_i $$,则概率分布的基尼系数定义为:
$$ Gini(D)= \sum{i=1}^n p_i(1-p_i)= 1-\sum{i=1}^n pi^2$$ _
其中,D表示数据集全体样本,$$ p_i $$表示每种类别出现的概率。取个极端情况,如果数据集中所有的样本都为同一类,那么有$$ p_0 =1 $$,
Gini(D)=0,显然此时数据的不纯度最低。
与信息增益类似,我们可以计算如下表达式:$$ \Delta Gini(X)=Gini(D)-Gini_x(D) $$
上面式子表述的意思就是,加入特征X以后,数据不纯度减小的程度。很明显,在做特征选择的时候,我们可以取$$ \Delta Gini(X) $$最大的那个。
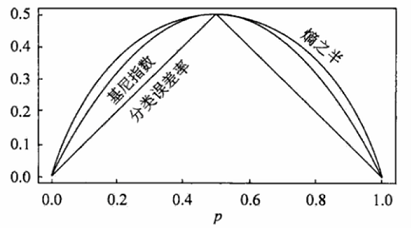
信息熵与Gini指数的关系
信息熵在x=1处一阶泰勒展开就是基尼指数,泰勒公式如下:
$$ f(x)= \dfrac {f(x_0)} {0!} + \dfrac {f'(x_0)} {1!} (x-x_0) + \dfrac {f''(x_0)} {2!} (x-x_0)^2 +...\dfrac {f^{(n)}(x_0)} {n!} (x-x_0)^n +R_n(x) $$
f(x)=-lnx在x=1处一阶泰勒展开,忽略掉高次项,可以得到f(x)≈1-x。这样$$ p_ilog_2p_i≈p_i(1-p_i) $$
另外,基尼系数和熵之半(也就是熵的一半值)的曲线比较近似。