特征工程是指为机器学习算法创造新特征的过程,这是提高模型预测表现的有力手段。
创造新的特征是一件十分困难的事情,需要丰富的专业知识和大量的时间。机器学习应用的本质基本上就是特征工程。
——Andrew Ng
通过特征工程,我们可以将数据中的关键信息分离出来,让数据中的模式浮现,并且可以结合自己的专业知识更有效的进行处理和分析。但特征工程的开放性使得这个过程不容易顺利的进行下去。
下面将为大家呈现20个在特征工程中最为有效和启发式的知识点,伴你畅游特征工程的世界。
1 什么“是”特征工程?
特征工程是机器学习界一个非正式的术语,由于机器学习的快速发展,出现了各种各样对于特征工程的定义,至今没有统一的标准答案。我们在这里给出了我们对于特征工程的理解和定义:
特征工程是基于已有特征创造新的特征并改善模型性能的过程。
一个典型的数据科学处理流程长这样:
项目调研/数据收集
探索性分析
数据清洗
特征工程
模型训练(包括交叉验证和超参数的精调)
项目交付和见解
2 什么“不是”特征工程?
这意味这在数据科学里的一些处理步骤并不是特征工程:
最初的数据收集
创造目标变量
数据清洗(移除重复变量、处理丢失的数据、修正遗失的标签等工作)
规模化或者归一化(交叉验证过程)
利用PCA选取特征(属于交叉验证过程)
需要强调的是以上只是我们的定义概念和分类,而对于这样的定义和分类却是因人而异的。
3 指示器变量
特征工程将要首先介绍的是用于分离关键信息的指示器变量。
这个时候你也许会有疑问“难道不应该利用算法自己去学习处关键信息嘛?”
然而事情并不是这样的,这取决于我们拥有的数据量和竞争信号的强度。可以通过事先的强调来帮助算法聚焦于重要的特征。
来自阈值的指示器变量:例如我们研究美国消费者的酒精偏好时,数据集内包含着年龄特征age,这时候就可以创造一个指示器变量age>=21来区分达到法定饮酒年龄的人群。
来自多特征的指示器变量:你需要通过手上的两个特征n_beadrooms和n_bathrooms来预测房价,如果两室两卫的房产时可出租的优质资产,你就可以建立一个指示器变量来标记它。
针对特殊事件的指示器变量:你正在为电子商务网站的每周销量建模,这时候你就可以创造两个指示器变量来表姐黑色星期五购物节和圣诞节。
针对某一特征组的指示器变量:你正在进行网站转化率的分析,数据集中包含分类特征traffic_source。你可以建立一个新的指示器变量paid_traffic来标记流浪来源价值的观察结果,是facebook的广告和还是google的广告来的好呢?
4 交互特征
接下来特征工程中将要介绍两个或者多个特征间的交互:
你记忆中有没有听过这样的话:“整体优于部分”?实际上一些特征可以结合起来提供比单个特征更多的信息,甚至你还可以对他们进行加减乘除等操作来获得更有效的特征。
*注:我们不建议使用自动循环来对所有特征获取相关的操作,这会导致“特征爆炸”。
两个特征相加:你想要通过预售数据来预测收入,通过sales_blue_pens和sales_black_pens相加,你可以得到sales_pens的总销量;
两个特征差异:同样也可以根据房屋的建造时间(house_built_date )和购买时间差(house_purchase_date)来得到房屋购买时的年限(house_age_at_purchase)
两个特征相乘:当你要进行售价测试的时候,你可以通过售价price和指示器变量conversion相乘来得到新的特征earnings。
两个特征相除:当你在对市场竞争对手分析时,可以通过点击率(n_clicks)和网页打开次数(n_impressions)相除来得到点击率click_through_rate来更好的分析对手数据。
5 特征表示
接下来将要介绍特征工程中简单但是十分有效的部分,特征表示:
你得数据可能并不是理想的格式,你需要考虑是否可以利用不同的方式表示数据以获得更多的信息。
日期和时间特征:例如购买日期和时间(purchase_datetime)会比一周内的购买日(purchase_day_of_week )和一天内的购买小时(purchase_hour_of_day)特征更为有效,同时你还可以建立过去三十天的购买量(purchases_over_last_30_days)这样的特征来增强数据所能表达的信息;
数值到分类的映射:你可以将在校的年数(years_in_school)分别转变为小学、初中、高中的各个年级特征(grade);
合并稀疏分类:如果一些分类只有很少数量的样本,可以将这些类别统一归并成一大类“Other”;
创造虚拟变量:这取决与机器学习算法的实现,也许需要手工将类别特征转换到虚拟变量中去(在合并稀疏类后)。
6 外部数据
在特征工程中外部数据很多情况下没有被重充分利用,实际上它们可以为模型的性能带来最重大的突破。例如定量对冲基金就通过各种不同金融数据源的层叠来进行研究。机器学习中的很多问题可以通过外部数据的引入得以解决,例如以下的一些实际应用:
时间序列数据:在利用时间序列数据时你只需要类似日期的特征就可以将不同的数据集进行叠加;
外部API:外部的API可以帮助我们得到更多的特征,例如微软的计算机视觉API就可以通过一张图像返回很多人脸数据;
地理编码:但我们拥有州、城市和接到地址的时候,你就可以将他们编码成经纬度,这将有助于你在其他数据集的帮助下计算人工统计资料;
异源的相同数据:想象以下你能用多少种方式追踪Facebook的广告竞价,可以利用facebook自集的追踪工具、谷歌的分析结果以及其他第三方软件,它们都会提供一些其他所不具有的信息。并且,数据间的任何差异都将为我们带来更多的信息。
7 错误分析(建模后处理)
特征工程的最后一项内容我们称之为建模结束后的错误分析。错误分析涉及广泛的内容,包括误分类的分析或者模型中观察到的高错误率,通过这些来决定下一步的改进方向。也许改进的方向包括收集更多的数据、拆分问题、针对误差创造新的特征。当利用误差分析来进行特征工程时,你需要理解为什么你得模型会失效。
下面时具体的操作方法:
从大误差开始:误差分析更多的是一个手工处理的过程,由于时间有限,我们建议你从大误差的那些地方开始,寻找你可以建立新特征的模式;
类型分割:另一种技术是将观测值分割并分别与平均误差进行比较,可以尝试为误差最高的部分建立指示器变量;
非监督聚类:当你在分类遇到问题时,可以在误分类的观测上运行非监督的聚类算法。我们不建议盲目地使用聚类作为新的特征,但这会使得模式识别更为容易,自始至终都要记得我们的目标是找到为何会观测到误分类;
向同事和领域专家咨询:上面三条都失效的情况下可以向同事和专家请教为何分类的表现如此糟糕。
8 结 论
特征工程有着无穷的可能。我们将最常见最有用的二十条建议列举在这,但是一定还有更多的好方法等待你得发现。
下面的指导方针一定要铭记在心——对于工程师来说,什么是好的特征?
可利用未来观测进行计算;
可凭直觉检验;
可以利用领域知识或者探索分析来检验;
必须具有可预测的潜质;
永远不要触碰目标变量:初学者经常会陷入这个陷阱,无论你建立新的指示器变量或者交互特征,永远不要使用你得目标变量,这会造成十分严重的误差后果。
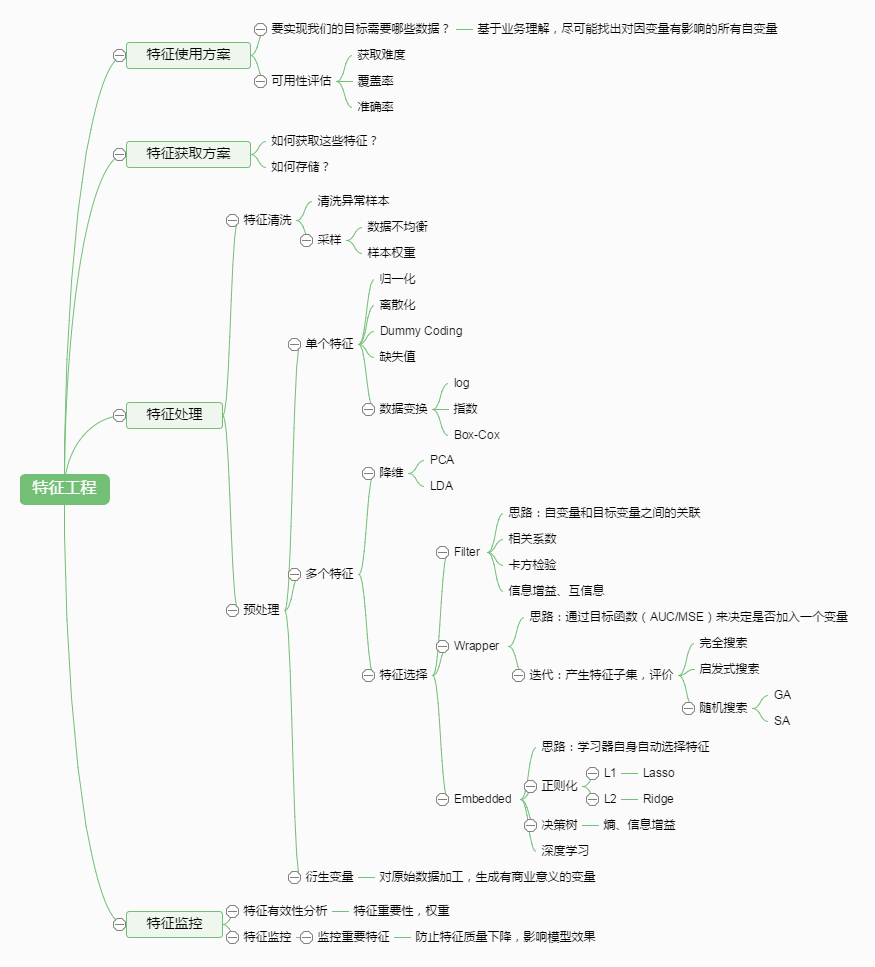

http://www.jianshu.com/p/0c3d95d11e3f
https://www.zhihu.com/question/47873540
https://www.zhihu.com/question/28641663
https://tech.meituan.com/machinelearning-data-feature-process.html
http://blog.csdn.net/a353833082/article/details/50765671
【持续更新】机器学习特征工程实用技巧大全
https://zhuanlan.zhihu.com/p/26444240?utm\_medium=social&utm\_source=wechat\_session