SLAM入门+典型SLAM应用及解决方案
https://zhuanlan.zhihu.com/p/28574164?utm\_source=wechat\_session&utm\_medium=social
SLAM技术入门
SLAM是simultaneous localization and mapping的简写,中文直译为同时定位与建图,其中又以定位更为核心,建图实际上是在定位的基础上,将观测数据进行融合的过程。关于定位,我们或许听过很多相关的术语,GPS(全球定位系统),基站定位,WIFI定位,陀螺仪等等;但以上定位方案无论是适用场景,还是精度,抑或是价格,对于常见的SLAM应用都不能满足需求,因此需要寻求更好的定位解决方案。
定位本质上可以定义为一个估计问题,通过传感器的观测数据(存在不同程度的噪声)来估计位置;也可以定义为一个优化问题,通过多种观测数据之间的约束关系,对位置进行优化。逻辑上,噪声越低的传感器能够获得更好的定位精度,但需要在价格和精度上寻求balance;目前行业中使用的传感器有:激光雷达(单线、多线,能够获得对应点的深度信息),深度摄像头(TOF,结构光,双目;三种方案各有优缺点,能够获取彩色和深度图像),IMU(惯导单元,能够获得高频的位移信号),彩色摄像头(单目,鱼眼,或者是经过特殊的设计获得更大的FOV),码盘(记录累积里程,累积误差大);可以参考这个链接获取更多的信息:
对于定位,通常意义上我们都指绝对定位,比如我们的GPS,固定原点位置,所有的定位都以这个原点作为参考,并以经纬度表示;又比如建筑物内部,我们规定一个原点,其他的定位结果都已这个位置为参考,并加上度量衡(cm, m等)表示。另外,在SLAM中我们也考虑相对定位(或者称为相对位移),当前时刻想对于前一时刻的旋转、平移量是多少,并且可以通过时序的累积得到绝对定位。
关于SLAM入门,在这里把几个相关的资料list出来:
- slamcn主页:
- 大神Andrew Davison的主页:
- openslam:
泡泡机器人,微信公众号
《视觉SLAM十四讲》,高翔,总结比较全面,同时有对应的code可以参考
slam基础知识:
感兴趣的朋友可以关注一下上面的材料。
从如下3个方向简单介绍SLAM技术的入门,又以视觉SLAM技术为主。
1. 激光雷达定位
使用激光雷达进行定位一般情况下包含建图、定位两个过程;当然,单线和多线激光在处理时是有差异的,在此以单线激光为例。
单线激光能够获取到某一平面上以激光位置为参考的点的深度信息,一周常见的是上千个点左右;他能够很好的捕捉场景以某一平面为参考的轮廓信息。

结合如码盘等完成建图,获取2d的平面图,建好的地图参考这个图片:
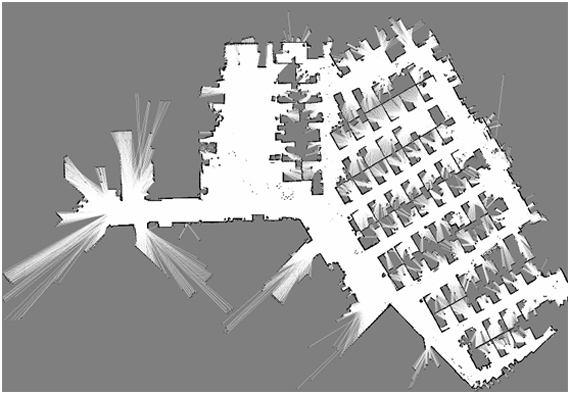
通过这个图片,我们大致能够判断这个地图是办公区,然后工位信息相对准确。
定位过程可以简单的理解成,通过当前激光的观测数据,同地图信息匹配得到定位位置;当然这中间需要使用相对的位移的信息,在此不进行更多的介绍。
当环境变化较小(即地图信息不需要频繁更新)的情况下,激光雷达能够获得很好的定位精度以及定位的连续性。但对于周围环境变化较快,比如商场的公共区域,存在很多行人的情况,激光雷达定位需要做特殊处理。
2. 视觉SLAM技术
着重介绍基于视觉的SLAM技术,并且参考ORB_SLAM为例说明一个完整的视觉SLAM系统需要的多个模块。可以参考这个链接学习相关内容:
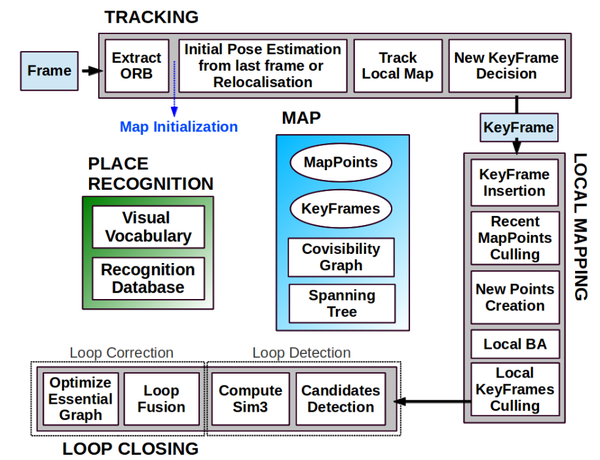
从上图,我们大致可以将SLAM分成如下几个模块:
前端,完成VO的功能
后端,对VO的结果进行优化和融合
建图,在优化之后的定位结果上进行地图的构建
回环,当到达之前去过的位置时,通过回环进行全局的优化,减小累积误差
a1. 前端VO
VO的目标是计算两个图像帧之间的相对位移关系,由于很多时候存在深度图像,所以可以将VO分成3d-3d, 3d-2d, 2d-2d等多种情况(注意:2d-2d的方案没有尺度信息,需要想办法从其他地方引入),流程如下:
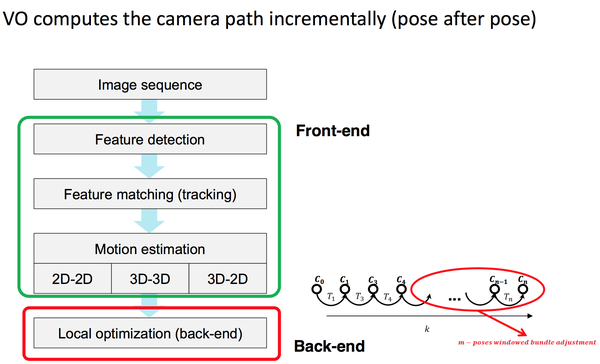
实际当中面临的问题主要是特征点的选择(精度,计算时间的平衡),配对算法的选择,以及R,T计算方法的选择。
但连续两帧之间VO的计算存在较大的累积误差,同时也并没有完整的利用帧间信息,VO基本上使用的是t,t+1时刻的信息,但实际上t+2时刻和t时刻可能同时获得某些特征点的观测信息,因此可以考虑将这些非相邻帧之间的观测信息作为约束条件,进行局部的优化,常见的如local BA
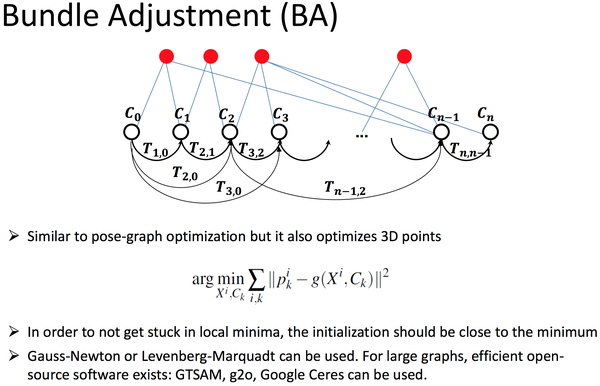
通过这个优化,我们可以认为获得了较好的前端VO数据。
a2. 后端优化
后端优化大体上有基于滤波和基于优化的两种方案。关于两种方案的实现都有多种方法,在此不进行详细介绍,因为很重要,还请读者自行学习。不过总结各自的优缺点:
EKF滤波方案:
滤波器方案一定程度上假设了马尔可夫性,但这个在实际场景中通常不一定满足;
EKF方案在小范围可以近似线性,但是在较大范围时存在非线性误差;
EKF需要存储状态量的均值和方差,随着路标数量的增大,状态两呈平方级数增加(协方差矩阵)。
基于优化的方案:
基于优化的方案目前使用越来越多,但也存在着长时间运行的规模问题
a3. 建图
建图很多情况下需要根据具体的需求决定,比如需要3d的点云地图,那就可以通过定位结果对点云数据进行融合;比如需要2d地图数据,则可以通过截取3d地图的某一个高度范围的点云并投影到某一个平面来获取;其他的比如octomap等。总体来说建图是根据需要决定的。
a4. 回环检测
回环检测实际上完成了一个非常重要的功能,就是当目标运动到之前到达过的场景的时候,可以通过这个新的观测,完成对地图以及定位的整体优化。方法上,主要解决闭环识别的问题。逻辑上,人是通过什么方法判断自己是否到达过某一区域呢?
我们通过当前的图片信息,和之前存储过的关键帧信息进行比对,或者是进行search,通过相似程度判断是否到达过对应的区域。所以任何用来进行相似图片判断的方案都可以用到这个场景,比如ORB_SLAM中基于bow的方法。
3. 多传感器融合
传感器融合是一个趋势,也或者说是一个妥协的结果。为什么说是妥协呢?主要的原因还是由于单一的传感器不能适用所有的场景,所以我们寄希望于通过多个传感器的融合达到理想的定位效果。
简单的,目前行业中有很多视觉+IMU的融合方案,视觉传感器在大多数纹理丰富的场景中效果很好,但是如果遇到玻璃,白墙等特征较少的场景,基本上无法工作;IMU长时间使用有非常大的累积误差,但是在短时间内,其相对位移数据又有很高的精度,所以当视觉传感器失效时,融合IMU数据,能够提高定位的精度。
再比如,无人车当中通常使用差分GPS+IMU+激光雷达(视觉)的定位方案。差分GPS在天气较好、遮挡较少的情况下能够获得很好的定位精度,但是在城市高楼区域、恶劣天气情况下效果下降非常多,这时候融合IMU+激光雷达(视觉)的方案刚好能够填补不足。
实时SLAM技术是从业者的一个追求,之前有一个链接做了很好的总结:
在这里将一些SLAM算法list如下,方便大家学习:
比较有代表性的几个工作 PTAM, LSD-SLAM, ORB-SLAM
ROS中融合的RGBD-SLAM, RTAB-SLAM
稠密、半稠密、稀疏的方案等 LSD-SLAM, SVO, DSO, DVO
多传感器融合的方案,如MSCKF, OKVIS等
主要是罗列一些关键词,方便大家检索
几个典型的SLAM应用场景及解决方案
slam技术目前在很多场景都有需求,有些是产品层面的真实需求,有些却是噱头。无论从哪个角度,我认为在某些应用场景当中,SLAM技术不可或缺。比如AR/VR设备,比如需要在室内自主移动的机器人,比如无人车,比如目前兴起的室内导航等。
1. AR/VR设备
AR/VR目前来看,依旧有很多问题需要解决,但AR/VR设备自身的定位问题是需要解决的核心之一。移动的AR/VR设备由于其耗电、功耗,设备尺寸、重量等的原因,有诸多的特殊性。
关于这个问题,请大家先参考这两个链接:
总结起来,AR/VR设备中的SLAM解决方案基本上就是视觉+IMU(VIO)的方案,不过需要综合考虑设备耗电、功耗的问题;因此有很多厂商在做软硬件一体化的事儿,将某些耗电、耗时的算法通过芯片等来完成。
针对这个领域,我个人有一个观点,或许会出现一个统一的解决方案,成为标配。
2. 室内机器人
室内机器人,当有了自主移动的需求之后,就一定有对SLAM技术的需求;当然,我们也可以通过增强学习等使机器人具有可靠可控的移动能力,但目前来看,这个路还会比较遥远。
对于室内机器人,我个人建议的解决方案有两种,实际上就是含有激光雷达和不含有激光雷达的两种方案,摄像头基本上都是标配,因为室内机器人基本上会带有摄像头。
a1. 码盘+单线激光
a2. 码盘+IMU+深度摄像头
很多人会好奇,为什么会把精度不高以及累积误差较大的码盘放上,但实际经验看,在打滑不严重的情况下,码盘是最能用来应对复杂场景的。
3. 无人车
无人车需求非常强烈,个人观点如下的方案:
差分GPS+激光雷达+多摄像头(多个双目)+IMU+高精度地图
当然,除去成本因素,激光雷达或许可以省掉。
4. 室内定位(基于视觉)
基于视觉的室内定位,在AR/VR导航,以及GPS/WIFI基本上无法工作或者满足定位精度要求的场景很有用。
不知道大家有没有使用过微信的街景定位,通过拍摄一张室外的照片儿进行定位。可以简单的理解就是GPS加上图像匹配的方案进行的。在室内场景,这种方案依旧适用,但有一个问题,就是室内场景已经获取到的照片的位置真值的获取。最近看到一个解决方案是这样的:
a1. 采集待定位场景的连续视频数据(连续图片帧);
a2. 使用SFM的方案,进行室内的3d建模;
a3. 根据获得的3d模型,给图片帧赋予真值;
a4. 通过图像search 以及匹配的方法进行定位 / 或者是训练深度学习模型,input是图片,output是图片的位置真值,然后对新输入的定位图片进行回归。
以上方案目前来看,只解决了特定场景的定位问题,由于数据是在云端的,所以一定需要在线使用,因此定位的频率不会太高。
总结,SLAM技术目前还不是非常成熟,但需求却很多。我个人认为的趋势并不多,主要就一点,那就是:软硬件协同后的统一的解决方案,但针对各个应用场景存在tuning的空间
解释一下:
未来的硬件提供商、或者是操作系统提供商,给出统一的SLAM解决方案,包括硬件,软件,芯片,并逐步成为标配;
标配的方案会在成本层面进一步压缩,满足产品化的需求;
各个应用场景的开发者,可以针对具体的使用场景进行tuning,这种tuning不仅仅是技术、算法层面的,也可以有硬件、芯片层面。